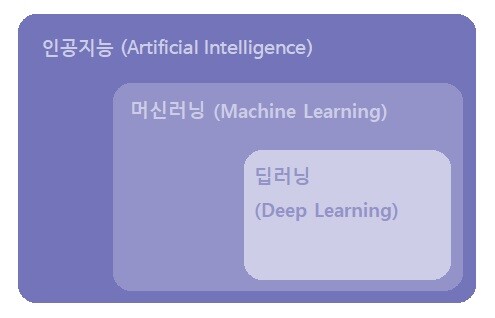
딥러닝과 머신러닝이 요즘 핫한 키워드로 떠오르고 있다. 그렇다면, 딥러닝과 머신러닝의 차이에 대해 알고 있는가? 구체적으로 말하자면, 딥러닝이 머신러닝에 포함된다. 머신러닝에는 없는 딥러닝의 특징은 무엇일까. 머신러닝과 딥러닝의 개념과 함께 그 차이점을 살펴보자.
우선 머신러닝은 인공지능의 한 분야로, 누적된 경험을 통해 컴퓨터가 스스로 학습할 수 있게 하는 알고리즘이다. 처리해야 할 정보를 더 많이 학습하기 위해 많은 양의 데이터가 필요하다. 알고리즘을 이용해 데이터를 분석 및 학습하고, 학습한 내용을 기반으로 어떠한 결정을 판단하거나 예측한다. 머신러닝은 작업을 수행할 때마다 얻은 결과를 스스로 학습하여 향후 작업을 더 정확하게 수행한다.
딥러닝은 머신러닝과 마찬가지로 인공지능의 하위 개념이며, 인공신경망에서 발전한 형태이다. 인공신경망(Artificial Neural Network)은 뇌의 뉴런과 유사한 정보 입출력 계층을 활용한 것으로, 블랙박스 형태로 데이터를 입력하면 자동으로 복잡한 수학식 모델링이 되는 기법이다. 딥러닝은 이러한 복잡한 인공신경망을 사용한 알고리즘을 통해 데이터를 학습한다.
머신러닝은 알고리즘이 부정확한 예측을 반환하면 엔지니어가 개입하여 조정해야 한다. 그러나 딥러닝은 알고리즘 자체 신경망을 통해 예측 정확성 여부를 스스로 판단한다. 또한, 딥러닝은 추상적인 정보를 인식하는 능력이 뛰어나기 때문에 머신러닝과 달리 개와 고양이를 식별할 수 있다. 머신러닝은 엔지니어가 미리 각 데이터가 개인지 고양이인지를 정의 내려야 하는 반면, 딥러닝은 개의 데이터와 개가 아닌 데이터들이 주어지면 자동으로 개인지 아닌지를 군집화하고 분류한다.
그렇기 때문에 딥러닝과 머신러닝은 쓰임새가 다르다. 많은 양의 데이터가 주어진 경우에는 딥러닝은, 그렇지 않은 경우에는 머신러닝을 활용하는 것이 효율적이다. 딥러닝이 활용되는 사례는 무엇이 있을까.

딥러닝을 활용한 대표적 사례로는 구글의 알파고이다. 알파고에 많은 양의 바둑 상황 데이터를 넣어두면 알파고가 상황에 맞는 적절한 판단을 스스로 내린다. 알파고는 가능한 모든 상황에 따라 이길 확률을 미리 계산하고 높은 확률의 수를 선택한다.
무인주행도 딥러닝을 활용해 발전하고 있다. 이전에는 신호가 바뀌었는지, 차가 있는지 등의 질문을 일일이 넣어주어야 했지만, 지금은 위험한 상황과 정상인 상황을 모두 포함한 수많은 데이터를 넣어두면 컴퓨터가 데이터를 학습해 자동으로 상황을 파악한다.
우리가 쉽게 접하는 페이스북에서도 딥러닝이 활용된다. 페이스북에서 얼굴 사진을 올리면 자동으로 해당 이름이 태그된다. 이는 딥러닝 기술로 얼굴을 인식 및 분류하는 딥페이스 알고리즘이다. 인식의 정확도는 인간이 인식한 것과 거의 유사하다고 한다.
네이버에서도 음성 검색에 딥러닝을 활용하고 있으며, 뉴스 요약이나 이미지 분석에도 적용하고 있다.
이렇게 딥러닝은 수많은 상황을 스스로 파악하여 판단할 수 있지만, 아직 일어나지 않은 일들에 대해서는 판단하기 힘들다. 이 때문에 다양한 상황의 데이터를 수집하고 상상하지 못하는 일들에 대한 대처도 고려할 필요가 있다.
[ⓒ CWN(CHANGE WITH NEWS). 무단전재-재배포 금지]

![[신명호 칼럼] 과학의 속성, 과학적 실천과 과학 공동체](https://cwn.kr/news/data/2026/04/20/p1065599396560987_185_h.png)


![넷앤드, 파트너십으로 한국 보안 우수성 알릴 것 [다국어]](https://cwn.kr/news/data/2026/03/13/p1065581137999459_473_h.jpg)
