
이번 기사에서는 식품의약품안전평가원의 설명을 기반으로 암과 관련된 독립형 소프트웨어 의료기기에 대해 알아보자.
독립형 소프트웨어 의료기기가 무엇인지 궁금하다면 “위드 코로나 시대, 인공지능은 어디로 가고 있을까?” 기사를 참고하길 바란다.
관련 기사: 위드 코로나 시대, 인공지능은 어디로 가고 있을까?
위드 코로나 시대, 인공지능은 어디로 가고 있을까?-2탄
먼저, 컴퓨터용 그래픽처리장치 및 멀티미디어 장치 기업 엔비디아(NVIDIA)의 '엔비디아 디지트(NVIDIA DIGITS)'이다. 이는 딥러닝을 기반으로 촬영된 환자의 영상 속 암세포를 판별해 표시해주는 암 진단 소프트웨어 의료기기이다.
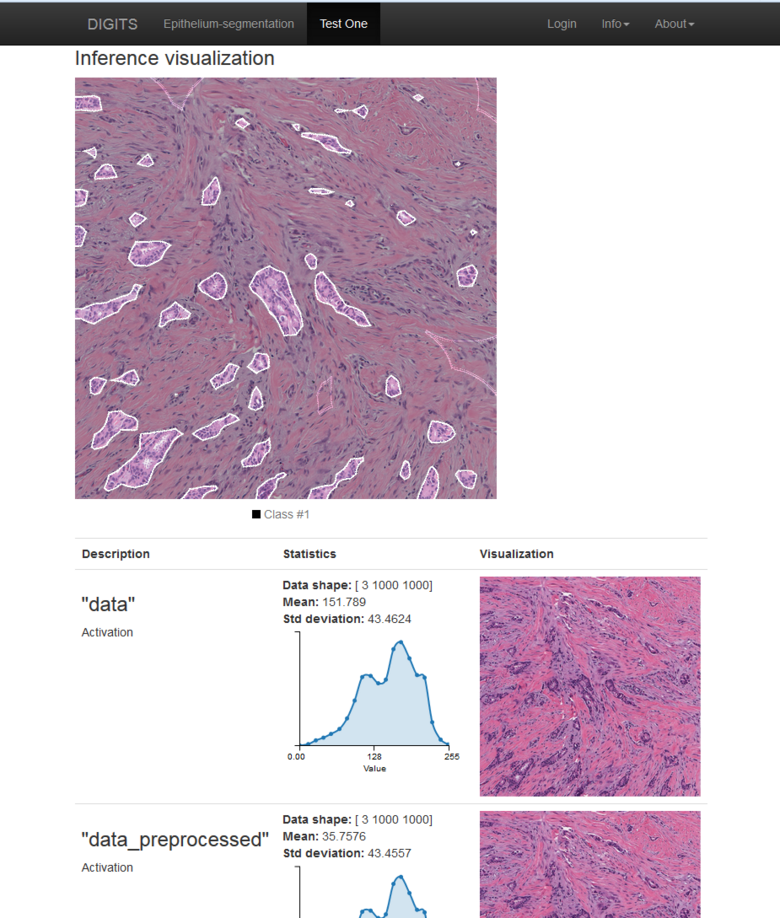
엔비디아의 딥러닝 GPU 훈련 시스템인 디지트는 엔지니어와 데이터 과학자가 딥러닝 기술을 기반으로 기존의 프로그래밍 및 디버깅 없이 네트워크 설계를 통해 이미지 분류, 세분화 및 물체 감지 작업을 위해 매우 정확한 심층 신경망(DNN)을 신속하게 훈련하는 데 사용할 수 있는 기술을 말한다. 특히, 데이터 관리, 다중 GPU 시스템에서 신경망 설계 및 훈련, 고급 시각화를 통한 실시간 성능 모니터링, 배포를 위한 결과 브라우저에서 최상의 성능 모델 선택과 같은 일반적인 딥 러닝 작업을 단순화할 수 있어 매우 효율적인 기술이다.
그 다음은 마이크로소프트의 프로젝트 하노버(Project Hanover)이다.
이는 머신러닝 기법을 이용해 암진단과 만성질환 진단을 진단하는 것을 돕는 독립형소프트웨어 의료기기이다.

암이나 여러 만성 질환을 치료하기 위해 개발하는 약물은 사람에 따라서 효과가 있을 수도, 그렇지 않을 수도 있다. 무작정 여러 가지 약물로 치료를 시도하는 것은 목숨을 걸어야 할 수 있는 상황이다. 부작용 또한 알 수 없다. 하지만, 프로젝트 하노버로 기계 판독을 거치면 환자의 고유 특성을 분석할 수 있고, 약물을 논리적으로 위험하지 않게 사용할 수 있다. 현재보다 더욱 발전된 퍼스널 치료가 가능해진다는 이야기이다.
그럼, 여기에서 궁금한 점이 있을 것이다.
앞서 소개한 두 독립형 소프트웨어 의료기기는 각각 딥러닝과 머신러닝을 기반으로 한다고 소개했다. 그렇다면, 딥러닝과 머신러닝의 차이점은 무엇일까?
먼저, 딥 러닝(deep structured learning, deep learning)이란 심층 학습이라고도 하는데, 여러 비선형 변환기법의 조합을 통해 높은 수준의 추상화를 시도하는 기계 학습 알고리즘의 집합을 뜻한다.

다양한 심층 기계 학습 모델이 있지만, 인공 신경망의 한 종류인 심층 신경망이 가장 많이 사용된다. 이 중에서도 콘볼루션 신경망(CNN), 심층 순환 신경망(deep RNN), 심층 오토 인코더(deep autoencoder) 등이 대표적으로 활용된다.
기계학습이라고도 불리는 머신러닝은 컴퓨터를 인간처럼 학습시킴으로써 인간의 도움 없이 컴퓨터가 스스로 새로운 규칙을 생성할 수 있지 않을까 하는 발상과 함께 시작되었다. 시대의 발전에 따라 사람조차 명확하게 구분할 수 없는 지식을 구현해야 하거나 사람이 일일이 구현하기에는 너무 많은 양의 규칙들이 필요한 상황이 발생해, 사람에게 도움을 주기 위해 개발되었다.
머신러닝은 일정량 이상의 샘플 데이터를 입력한 후, 입력받은 데이터를 분석해 일정한 패던과 규칙을 찾아낸다. 마지막으로 찾아낸 패턴과 규칙을 가지고 의사결정 및 예측 등을 수행하는 순서로 동작한다.
컴퓨터는 사람처럼 지각능력을 갖추고 있지 않기 때문에 특징량(특정 벡터들이 모여 있는 것)을 바탕으로 벡터(vector)를 구분해낸다. 이렇게 생성된 특징량을 바탕으로 구분선을 찾아내는 것이 바로 머신러닝이다. 그런데 벡터를 구분해내려면 데이터를 벡터로 변환해야 한다. 이를 위해 사용되는 것이 ‘특징추출(feature extraction)’이다.
또한, 구분선을 찾아내야 하기 때문에 ‘회귀 분석(regression analysis)’를 사용한다. 통계학에서 주로 사용되는 회귀 분석(regression analysis)이란 여러 자료 간의 관계성을 수학적으로 추정하고 분석하는 데이터 분석 방법의 하나이다. 이러한 회귀 분석은 주로 시간에 따라 변화하는 데이터나 가설, 인과 관계 등의 통계적 예측에 사용된다.
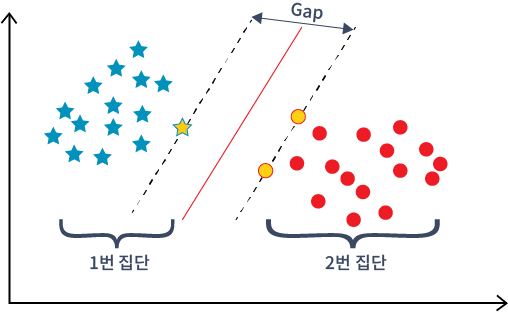
다시 본론으로 돌아와서, 머신러닝과 딥러닝은 어떤 차이가 있을까?
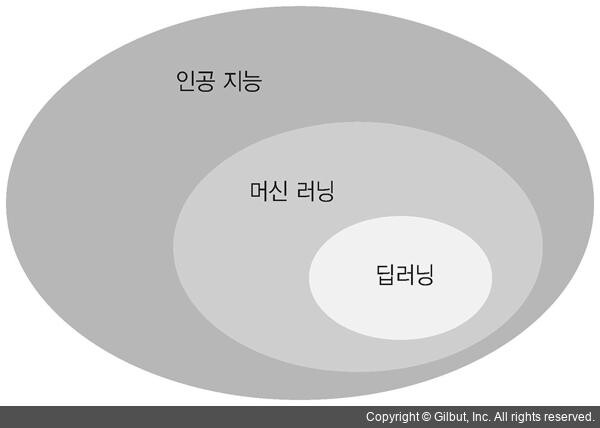
딥러닝은 앞서 설명한 바와 같이, 여러 층을 가진 인공신경망(ANN)을 사용하여 머신러닝 학습을 수행하는 것으로 심층학습이라고도 부른다. 따라서 딥러닝은 머신러닝과 전혀 다른 개념이 아니라 머신러닝의 한 종류라고 할 수 있는 것이다.
기존의 머신러닝에서는 학습하려는 데이터의 여러 특징 중에서 어떤 특징을 추출할지를 사람이 직접 분석하고 판단해야만 했지만, 딥러닝에서는 기계가 자동으로 학습하려는 데이터에서 특징을 추출하여 학습하게 된다. 이처럼 딥러닝과 머신러닝의 가장 큰 차이점은 바로 기계의 자가 학습 여부로 볼 수 있다.
따라서 머신러닝은 컴퓨터를 인간이 학습시키는 것이고, 딥러닝은 기계가 자동으로 대규모 데이터에서 중요한 패턴 및 규칙을 학습하고, 이를 토대로 의사결정이나 예측 등을 수행하는 기술로 정의할 수 있는 것이다.
지금까지 암과 관련된 독립형 소프트웨어 의료기기에 대한 소개와 그에 사용된 딥러닝과 머신러닝의 차이점까지 알아보았다.
다음 기사에는 안과 질환, 퇴행성 파킨슨 증후군 진단, 뼈 연령 진단에 사용될 독립형소프트웨어 의료기기에 대해서 소개할 것이다.
[ⓒ CWN(CHANGE WITH NEWS). 무단전재-재배포 금지]

![[신명호 칼럼] 과학의 속성, 과학적 실천과 과학 공동체](https://cwn.kr/news/data/2026/04/20/p1065599396560987_185_h.png)


![넷앤드, 파트너십으로 한국 보안 우수성 알릴 것 [다국어]](https://cwn.kr/news/data/2026/03/13/p1065581137999459_473_h.jpg)
