
인공지능이 나날이 발전하고 있는 요즘, 머신러닝과 딥러닝이 어떤 식으로 동작하는지 알아야 할 필요가 있다. 전공지식이 없는 사람도 알 수 있도록 최대한 쉽게 설명해보았다. 이 기사를 읽고 많은 사람이 딥러닝에 대한 관심이 생겼으면 하는 바람이다.
딥러닝은 급속도로 발전을 거듭해 현재 우리의 생활 속에서 많이 사용되고 있다. 누구나 딥러닝이 화제가 되고 있고, 무엇인가 어려운 일을 해내는 것임을 알고 있다. 그리고, 이러한 점에서 어려워 보이는 딥러닝을 다양한 분야에서 활용해 사람과 비슷한 혹은 사람보다 뛰어난 능력을 보여주는 기계를 구현하는 공학자들은 정말 대단해 보인다.
우리의 일상 속에 자연스럽게 사용되고 있는 딥러닝의 작동 원리는 무엇일까? 어떤 과정을 거쳐 기계가 사람처럼 행동하게 되는 것일까? 간단한 예제를 통해 이러한 질문에 대한 답이 될 수 있는 딥러닝의 핵심 절차들을 소개하겠다.
머신러닝 분야(딥러닝의 상위 범주)의 세계적인 권위자 앤드류 응(Andrew Ng)이 구글에 있을 당시에 개발한 고양이 분류 모델을 통해 살펴보자.
1. 데이터 세트(Data Set) – 기계가 공부하기 위한 책
딥 러닝은 머신러닝의 범주에 들어가며, 우리가 원하는 편의기능을 제공하는 기계를 만들기 위해 기계를 학습시킨다는 개념이다. 따라서 기계를 학습시키기 위한 자료가 필요한데 이것이 데이터 세트이다.

[그림-1] 기계의 학습자료 데이터 세트(Data Set)
고양이 분류모델을 만들 때, 기계의 학습자료로 다양한 고양이 사진을 활용한다. 기계에게 고양이 사진을 주기 전에 앞서 데이터 전처리 과정을 거쳐야 한다.
데이터 전처리란 데이터의 사용 목적에 맞게 기계가 사용 가능한 상태로 만드는 것이다. 그 과정에는 데이터의 실수화, 결측치 제거, 노이즈 제거, 과소포집과 과대포집 해결 등이 있지만, 뒤에서 거칠 전처리 과정에는 데이터의 분류, 시각적인 이미지를 기계가 이해할 수 있는 실수 데이터화 인 데이터의 실수화 및 압축이다.
전처리를 위해서 먼저 사진을 다음 3가지 용도로 쪼개야 한다. ‘학습용(Training set)’, ‘학습 검증용(Validation set)’, ‘학습 테스트용(Test set)’이다. 학습용과학습 테스트용은 말 그대로 기계에게 학습을 하라고 주는 책과 학습을 잘 했는지 테스트를 하는 책이다.
학습 테스트용이 학습이 완료된 기계의 최종 시험이라면, 학습 검증용은 기계가 학습용이라는 책을 읽으며 어떤 것이 고양이인지 공부하고 있는 과정에서, 학습을 잘하고 있는지 확인하는 퀴즈용 사진들이다. 만약 퀴즈의 정답률이 낮으면 학습 절차에 문제가 있다는 뜻이다.
사진을 3가지 용도로 분류한 다음에는 사진을 기계가 읽을 수 있는 언어로 가공해야 한다. 사진의 색상과 밝기 정보를 숫자화해서 한 줄의 벡터 모양으로 압축해서 기계에게 제공하는 것이다.
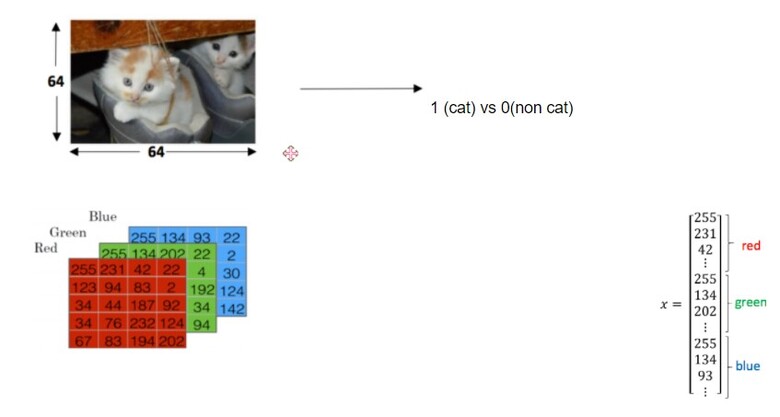
[그림-2]
2. 알고리즘 설계 – 기계의 뇌
다음은 기계를 설계하고 만들 차례이다.
딥러닝은 주로 사람의 뇌에 비유한다. 사람의 뇌는 뉴런 또는 신경이라는 세포 단위로 이루어진 신경망이며, 딥러닝은 인공 뉴런 또는 인공 신경이라는 단위로 구성된 인공신경망을 이룬다.
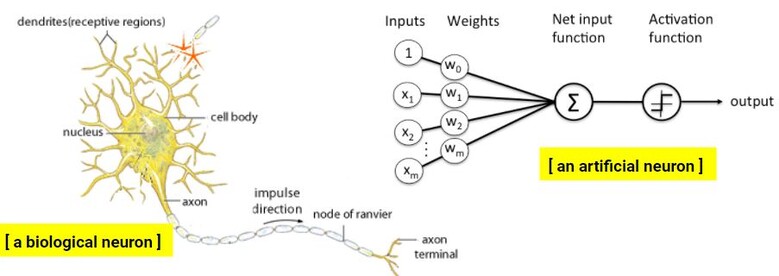
아래 왼쪽 그림이 사람의 신경세포인데, 가지처럼 뻗어 있는 신경 세포의 돌기들로 여러 가지 정보가 들어오면 일련의 과정을 거치면서 처리된 정보가 말단으로 가서 다른 뉴런으로 넘겨주는 기능을 한다. 이러한 뉴런들이 서로 연결되어 하나의 거대한 신경망(뇌)을 구축한다.
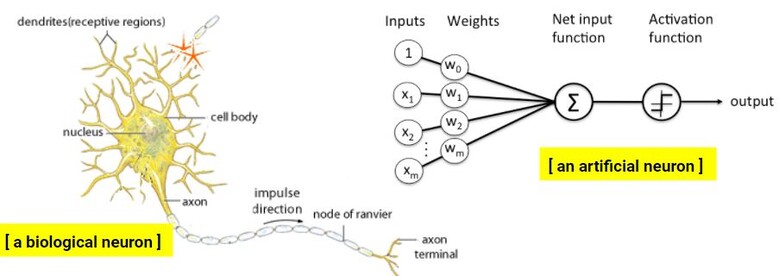
기계의 인공 뉴런도 비슷한 모습으로 설명할 수 있다. 인공 뉴런의 한쪽으로 여러 가지 입력 값이 들어오면, 각 입력 값의 비중에 따른 값을 곱해서 합한다. 그리고 활성화 함수에 값을 대입해주면, 해당 사진이 고양이인지 개인지 구분해주는 것이다.
활성화 함수는 기계의 기능에 따라 다양하게 사용되는데, 고양이 분류 모델과 같이 이진 분류(1 : 고양이 사진, 0 : 고양이가 아닌 사진)를 할 때에는 시그모이드 함수, Tanh 함수, ReLu 함수를 많이 사용한다. 만약, 기계가 고양이, 강아지, 토끼, 돼지, 소 등 더 많은 카테고리로 분류를 원한다면 Softmax 함수를 사용한다.
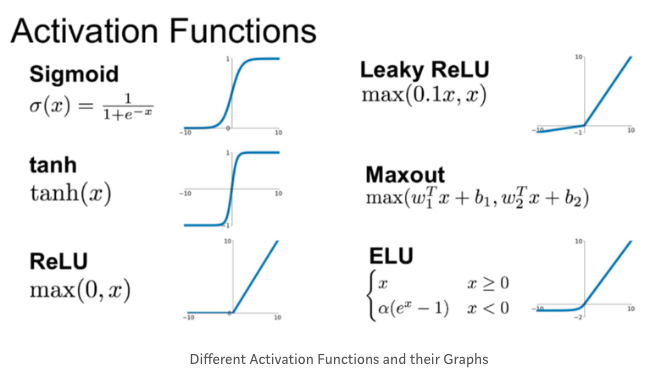
[그림-3]
위 고양이 분류 모델에서는 시그모이드 함수를 사용했다. 0과 1을 구분하는 이진분류에서는 아래의 계단 함수와 같이 x=0을 기준으로 y=0을 하나의 범주(고양이가 아닌 사진)와 y=1을 하나의 범주(고양이인 사진)로 나눈다.
시그모이드 함수는 계단을 굴곡이 있는 언덕으로 만들어서 y값을 0과 1사이의 실수로 출력한다. 이 실수를 확률로 활용해, 입력 값이 해당 범주일 확률로 해석할 수 있다.
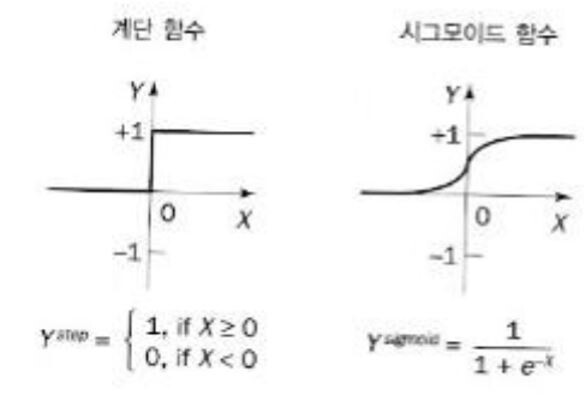
[그림-4]
기계가 학습을 하는 방법을 알기 위해서는 인공신경의 구조를 자세히 볼 필요가 있다. 학습경험이 전무한 신생아 기계가 있다고 가정해보자. 이 신생아 기계에게 고양이 사진을 보여주면, 고양이 눈의 위치, 귀의 모양, 코의 크기, 발바닥의 색깔 등 사진의 다양한 정보가 기계의 머릿속 인공 뉴런의 입력 값으로 들어간다.
각 정보에는 해당 사진이 고양이인지 판별할 수 있는 알맞은 비중이 존재하지만, 처음 고양이 사진을 본 신생아 기계는 그 비중을 알 수 없으므로, 처음에는 아무 값이나 넣어서 진행한다. 그리고 활성화 함수를 거쳐 기계가 사진을 구분(출력 값)하면 정답과 비교한다. 이처럼 인공 뉴런의 입력부터 출력방향으로 진행하는 것은 인공뉴런의 정방향 진행(Forward-propagation)이라고 한다.
[그림-5]
3. 반복 학습 – 기계의 학습
기계가 처음으로 고양이 사진을 접했을 때 입력 값에 따른 비중을 무작위로 했기 때문에, 곧바로 정확한 결과를 얻기는 힘들다. 기계가 고양이 사진을 정확히 구분하기 위해서는 알맞은 비중 값을 찾아야 하는데, 이것이 바로 기계의 학습 과정이다.
첫 사진에 대한 기계의 출력 값을 얻었으면 비중 값을 알맞게 수정하기 위해, 이번에는 이 출력 값을 갖고, 다음 그림과 같이 반대 방향으로(출력에서 비중 쪽으로) 인공 뉴런을 진행한다. 이처럼 인공뉴런의 출력부터 입력방향으로 진행하는 것을 역전파(Backward-propagation)이라고 한다. 그리고 이때 사용하는 방법이 경사 하강법(gradient descent)이다.
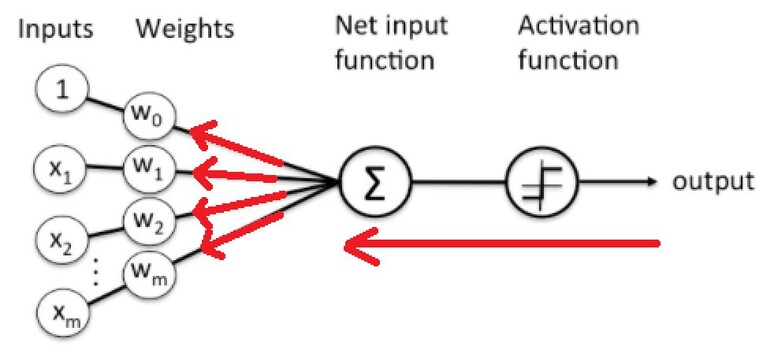
[그림-6]
경사 하강법은 정답을 향해 비중 값을 조금씩 이동시키는 것이다. 아래 그래프에서 가로축은 비중 값이고, 세로축은 Cost 값이다. Cost는 비용함수 값이며, 비용함수 값은 클수록 비중 값이 정답과 멀고, 작을수록 정답에 가깝다는 것을 의미한다. 즉, 아래 그래프의 최저 지점에 도달하는 비중 값을 찾는 것이 기계 학습의 목표라고 할 수 있다.
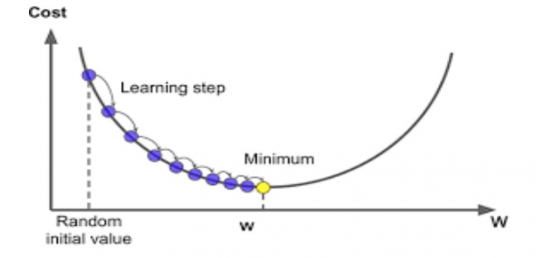
[그림-7]
첫 사진을 거쳐 비중 값을 수정했던 것처럼, 기계는 제공된 모든 책자(데이터 세트)를 활용해, 사진의 개수만큼 정방향 진행과 역전파를 반복해 비중 값을 업데이트하면서 최적의 값을 찾아낸다.
앞서 설명한 고양이 분류 모델은 단순히 해당 사진이 고양이인지 아닌지를 구분하는 단순한 이진분류를 딥러닝을 통해서 구현한 것이다. 우리가 실생활에서 접하는 다양한 딥러닝 알고리즘들은 보다 복잡하고 정확한 모델을 구현한 것이며, 고양이 분류 모델과 큰 틀에서 비슷한 과정을 거치지만, 사용되는 함수, 매개변수의 개수, 연결된 인경 뉴런의 개수 등이 다양하게 존재한다.
알고 보면 딥러닝은 쉽게 이해할 수 있다. 인공지능, 머신러닝, 딥러닝 등이 화제가 되고 급속도로 성장하고 있는 현재, 이 기사를 통해서 독자들이 기계가 어떻게 사람처럼 학습하고 기능하는지 간단하게 라도 아는데 도움이 되기를 바란다.
[ⓒ CWN(CHANGE WITH NEWS). 무단전재-재배포 금지]

![[신명호 칼럼] 과학의 속성, 과학적 실천과 과학 공동체](https://cwn.kr/news/data/2026/04/20/p1065599396560987_185_h.png)


![넷앤드, 파트너십으로 한국 보안 우수성 알릴 것 [다국어]](https://cwn.kr/news/data/2026/03/13/p1065581137999459_473_h.jpg)
